Search for Static Website Without External Service

When you have a static website, there are a few things that you usually don’t have out-of-the-box. One such thing is search. You can argue that you don’t need it, but if you want it and your site isn’t that large, I’ll describe how I’ve set it up without an external service.
This post is part 5 of my Hugo Pipeline Series, so I’ll use Hugo as the example here, but I’ve done a similar setup with this Gatsby plugin as well.
The steps I use are the following:
- Create a json file with everything I want in my search index (Hugo)
- Create a search index from the json file (NodeJS)
- Download and load the index (Web Browser)
- Perform search and present results (Web Browser)
1. Create file to index
I have a Hugo layout for the indexable content where I output all pages of the types I want. The type article is what all blog posts use and shortcuts-windows7 is a special layout I want to include in search (see it here, if you’re curious). My About page is not included, since I figure you can find that anyway if you can find the search feature 🤪
Title, relative permalink, tags, the full content as plain text, the summary (excerpt) and the date (formatted and raw), are the fields I picked as searchable + available for search result presentation.
I also exclude the list page named Articles (that I don’t know how to get rid of, please create a PR if you know how and want to help).
layouts/search-index/single.html
This layout needs to be referenced and for that I have search-index.md which is empty, except for the frontmatter.
---
date: "2017-06-21T06:51:27+02:00"
title: "search index"
type: "search-index"
url: "data-to-index.json"
---
2. Create index
Now that we have something to index, it’s time to switch to NodeJS land and install Lunr, yarn add lunr. I have a script that reads the file created in the previous step (data-to-index.json) and creates a new file, search-index.json in the output directory (public). This is also the place to configure Lunr with boosting and such. I’m not good att tweaking search, so these settings are pretty basic. This was written before I got more heavily into NodeJS development, but it has worked without problems for a few years now.
This is run with an npm script after Hugo has produced its output.
> node build/index-search.js public/search-index.json
Reading /Users/henrik/Code/blog-hugo/public/data-to-index.json
Indexing /Users/henrik/Code/blog-hugo/public/data-to-index.json
Saving index at public/search-index.json
Saved index at public/search-index.json
✨ Done in 0.52s.
To have the search index available during development, I run the Hugo command twice. This isn’t perfect, but since hugo server (like most dev servers) doesn’t save the files on disk, this is necessary and not really a problem. The npm script looks like this: hugo && npm run index && npm run hugo:watch (see full package.json here).
3. Loading index
Most of my visitors come straight to a post from a Google search, so I’m probably the biggest user of the site search myself (maybe the only one 😳). Therefor I don’t want the search index to be downloaded before the user has shown an intention to use the search feature. The index is currently a download of 134 kB (compressed), which I think is fine considering that people are watching video on web pages and that the alternative of using an external service has several other drawbacks (complexity, cost, etc). Still, the index size is worth keeping an eye on and this setup requires error handling (if the download fails or the user has started to type before the download is complete).
The index are downloaded through a regular fetch call when the search dialog is opened (the open function).
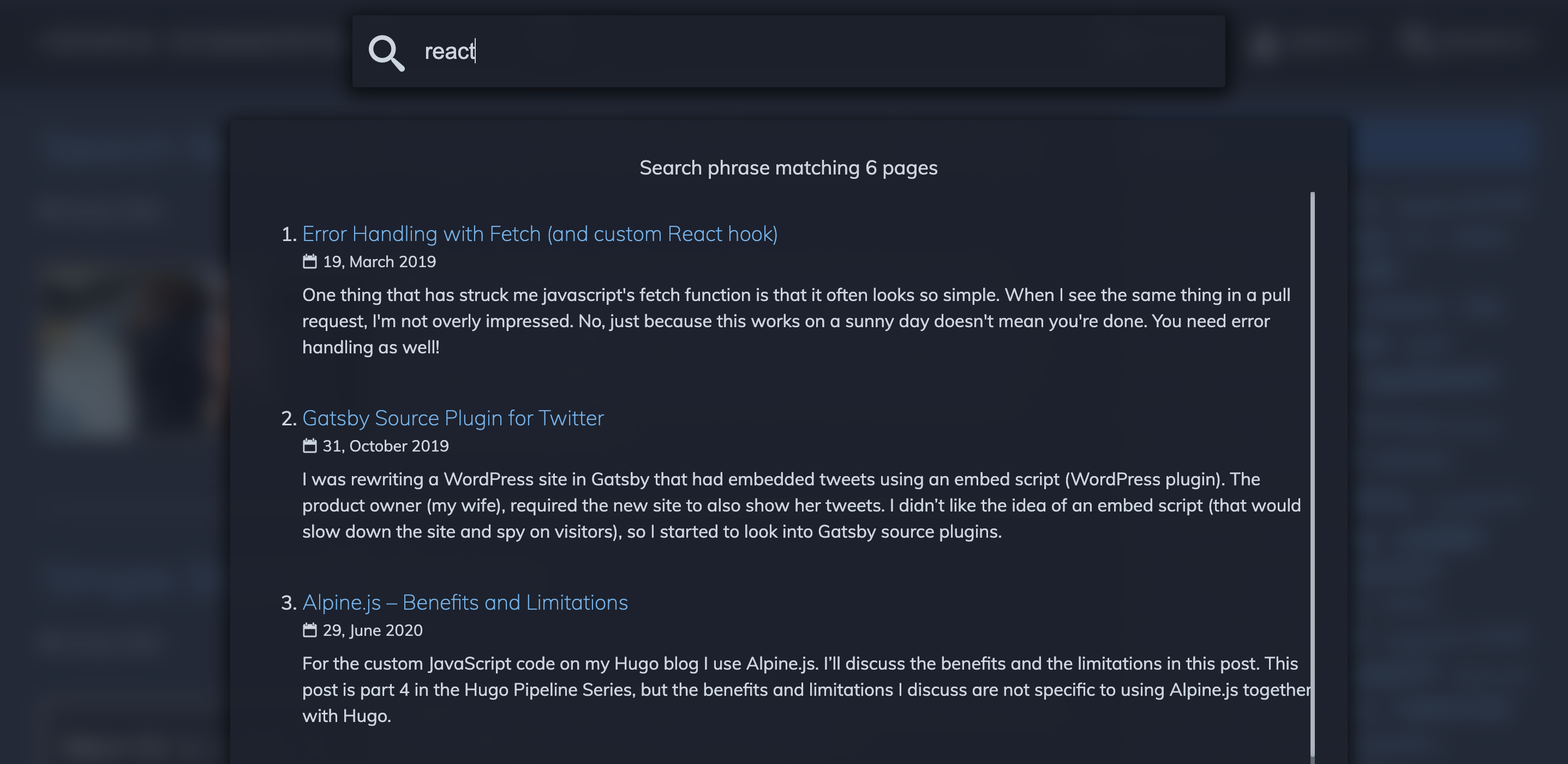
4. Searching and presenting results
I have touched on this in my previous post about Alpine.js, so go there for more code, but this is simply about calling the search function on the Lunr index. Since everything is in memory, I call the search function on every keypress in the searchbox.
Good luck in implementing your own site search!